
Lit mag Guernica implodes, LLMs beat neuroscientists, CS vs. Philosophy deathmatch, AI pollution reaches science
Desiderata #22: links and commentary


The Desiderata series is a regular roundup of links and thoughts, as well as an open thread and ongoing AMA in the comments.
1/9. Since the last Desiderata, The Intrinsic Perspective published:
(🔒) Recent AI failures are cracks in the magic. Trouble in trillions-land.
Here lies the internet, murdered by generative AI. Corruption everywhere, even in YouTube's kids content.
(🔒) Did novels stop mattering in the 2010s? Searching for literature's missing impact.
(🔒) Ask Erik Hoel: "If I take a job at Meta, should I go long-distance with my girlfriend?" TIP advice column #1.
AI keeps getting better at talking about consciousness. But does it matter?
2/9. As befits the running theme of the last few weeks, it’s become obvious that AI data pollution has reached the sciences. It’s disturbingly easy to find examples by searching the scientific literature for common AI stock phrases that made it through peer review. Like “Certainly, here is blah blah” in response to a clear request for summary, that the authors then copy-pasted.

You can get similar results for “As an AI language model.”

Or “I’m very sorry but.”
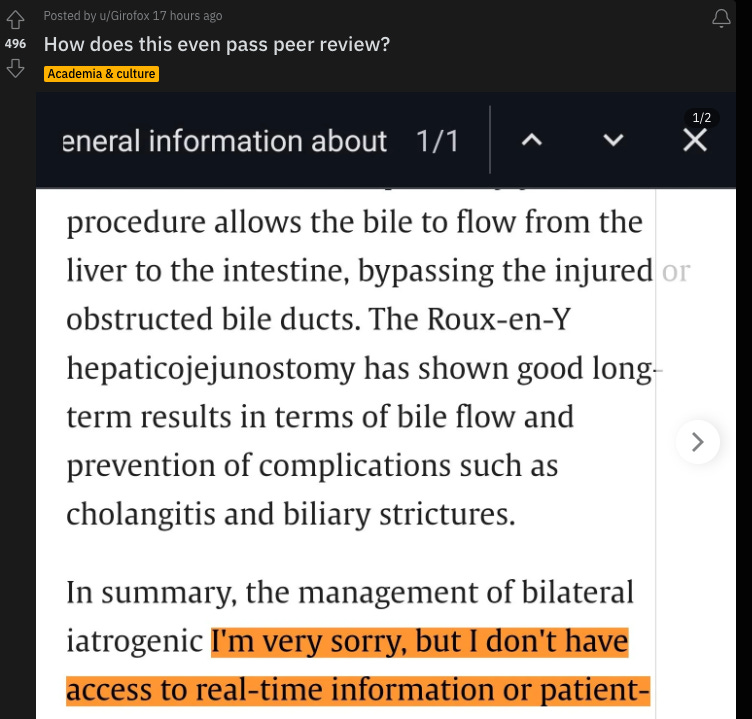
And so on, forever now. This is just the super obvious stuff, and users will get better at hiding it, but this is what I mean when I say there is a tenuously fine line, perhaps no real clear distinction at all really, between using AI for scammy purposes and using it the way it is intended: to do the cognitive work for you. Maybe some people will be able to ethically toe that line appropriately, but most won’t—at least not until there are clearer cultural norms.
3/9. Counterpoint! AIs can help science, not just pollute it. An international team of scientists published a pre-print claiming that LLMs do a better job predicting future neuroscientific results than actual human neuroscientists. Basically, the researchers created a new benchmark, Brainbench, that gives a score to how well you can predict future neuroscientific abstracts. It compares real abstracts to secret false abstracts that have been altered and you have to guess which is real. On this task LLMs did a way better job than the human neuroscientists (the dotted line on the left).

This might be pure human cope, but I worry about taking these sort of results too seriously. To create the dataset of false abstracts, the researchers used GPT-4 to modify existing abstracts. But what if LLMs are just really good at identifying the linguistic modifications that GPT-4 would make to abstracts in an attempt to disguise them? Perhaps to notice what modifications a LLM would make you have to be an LLM, and their success is not about predicting results but about attention to language. I’d love to see the same result replicated but with humans spending more time creating the false datasets. It’s sort of like you’re asking GPT-4 to investigate itself—is it not the best “person” for that?
3/9. Guernica, a well-known literary magazine, is currently in crisis after writer Joanna Chen, who lives in Israel, contributed a meditative personal essay on being torn amid the recent conflict. In it she tells this anecdote about a neighbor:
A neighbor told me she was trying to calm her children, who were frightened by the sound of warplanes flying over the house day and night. I tell them these are good booms. She grimaced, and I understood the subtext, that the Israeli army was bombing Gaza.
The “good booms” line led to many previous writers for Guernica pulling their pieces from the magazine, staffers quitting, and social media condemnation. In one way, it appropriately fit the theme—Guernica is the name of a Picasso painting depicting the Nazi bombing of a Spanish town.

But there seems to be some issues of reading comprehension: it’s quite clear that the line from the neighbor is supposed to make us wince, not nod in happy agreement.