
But Dumbo could already fly?
100% pure human copium about OpenAI solving Erdős problems


And lo, the machine thought, and thought, and thought, and one day it answered.
We finally have the first truly impactful intellectual contribution where explicit credit must be given to AI. It’s a historic moment. OpenAI released a disproof of a geometry conjecture first proposed by Paul Erdős 80 years ago, discovered by an unnamed internal model. According to Scientific American:
“No previous AI-generated proof has come close” to meeting those high standards, wrote Timothy Gowers, a mathematician at the University of Cambridge, in commentary solicited by OpenAI.
“This is the unique interesting result produced autonomously by AI so far,” says Daniel Litt, a mathematician at the University of Toronto, who was consulted by OpenAI to verify the proof but is not involved with the company.
The AI’s insight behind the finding is elegant (although the proof needed re-writing by humans to be clear and up-to-standard). There are many far greater problems in math, but it is still very much the definition of “new scientific or mathematical knowledge” which, for many—including myself—has been the highest bar when it comes to AI.
Now, “new information” is notoriously hard to define, since of course by any strict definition AI has contributed new information before (just think of all the protein structures that have come out of AlphaFold). But this discovery does seem different in kind, in that it is:
(a) Something verifiably true.
(b) Non-trivial or even important (at least, relatively so in its subfield of math).
(c) Something humans had spent previous time on and failed to crack.
(d) The AI was (reportedly) not purpose-built to solve this particular problem, but did so (reportedly) autonomously as a next-gen LLM similar to the current version of ChatGPT.
Intriguingly, the internal model succeeded by going the opposite of the expected direction. It disproved the optimality of what Paul Erdős thought to be essentially the best construction for this problem (some have suggested that the social pressure of Erdős’ authority pointed humans in the wrong direction). To put it as simply as possible, Erdős was asking: If you place a set of nodes down on a plane, how can you organize this set of nodes such that as many pairs of nodes as possible are an exact fixed distance apart?
Here is what the original thought-to-be-optimal construction looked like:
And here is the improvement, passing from human to post-human, in an image that will probably go down in history books:

In response to this development, many are crowing that human mathematics is over. Here’s a comment comparing this moment to when the game of Go fell to deep learning, which in turn heralded the modern AI age:

People are getting extremely confident about this.

EXCEPT… A CURRENT MODEL CAN ALREADY DISCOVER THIS?!?
Let’s review the implicit pitch of this announcement: That the newer internal model at OpenAI is a step up in capabilities, and therefore is becoming powerful enough to begin to automate mathematics itself.
But to actually show that scientifically, you need controls. Specifically, you need to show that previous models could not do this. Otherwise this could just be a function of search (and there was indeed probably a lot of search across all open Erdős problems until they got a hit). Or, there might be something uniquely easy about this problem. Or, the result could be via minor improvements in elicitation (“elicitation” means the work of getting the models to accomplish things via prompts or harnesses or even just asking in the first place). These don’t take away that AI solved something, but they would take away the implied conclusion: That the models are getting smarter and smarter at some fixed rate, and are soon to surpass humans.
Meanwhile, a very good mathematician was able to get the currently available-to-all ChatGPT 5.5 Pro to reproduce the output! Below is this being described by one of the mathematicians quoted in OpenAI’s initial release, Timothy Gowers, who in turn is quoting the mathematician Xiao Ma, who showed ChatGPT 5.5 could do it (Ma previously made progress on Hilbert’s 6th problem).


We don’t know everything about Xiao Ma’s result, but in general the rediscovery by ChatGPT 5.5 seemed unsurprising to many key players; and, importantly, we also don’t know everything about OpenAI’s results (did they rewrite the prompt a million times, did they actually fine-tune or somehow specialize the “internal model” but still call it the same “internal model” because there are no rules here, etc.).
In reply, the OpenAI researcher Noam Brown (who leads the reasoning team at OpenAI) said that the real impact of the discovery is that the new model shifts the intelligence curve and so makes such discoveries easier.



But I read the whole transcript of the exchange which elicited the exact same result from the publicly-available ChatGPT 5.5, and basically the only hints given are just saying that the disproof was already known, that it was asked to generate a few profound ideas, and then asked to expand on one of those ideas. That’s a pretty minimal set of prompts that could easily be automated. Just tell the model the problem is known to be solved, tell it to generate a set of profound ideas, and then tell it to pursue each one to the end sequentially. I feel like people probably already use the models like this all the time?
Does this mean that all that training, all that work internally, went into creating this super-duper model, and all it did (pretty much) was shift the “intelligence curve” to not needing to be told the problem was already solved? That’s an improvement in intelligence that looks a lot like Dumbo’s feather: Look, a billion dollars later, we don’t need the feather to fly!
So if you want to be super skeptical, then all we really know for sure right now is that their new internal model takes away Dumbo’s magic feather.

And what about ChatGPT 5.4? 5.3? You see where I’m going. I’m happy to admit there is some version that definitely could not, in a million years, be elicited to solve this problem. But I have no idea what version that is… and neither does anyone else.
Maybe that’s what progress on intelligence really is: just feather after feather being removed. Yet if we’re just a feather or two away, why aren’t tons more math problems falling right now? Is no one looking? What’s going on?!
THIS LOOKS EERILY SIMILAR TO ANTHROPIC’S MYTHOS ANNOUNCEMENT
In April, Anthropic made worldwide headlines by claiming that their new model, Mythos, was such a cybersecurity threat it couldn’t be released to the public. And there was probably some truth to that, in that some benchmarks showed marked increases—much as this internal model is likely better on certain math benchmarks (but all these things are getting harder to measure as we enter a post-benchmark age). At the same time, Anthropic’s flagship example of a zero-day exploit turned out to be replicable using existing models by just rigorously trawling the search space. Probably both were true: Mythos was a step forward, but also, in general, serious resources are not spent trying to find exploits, and it’s impossible to disentangle the actual intelligence gains vs. just Anthropic devoting its massive war chest of money, talent, and compute to some attention-bottlenecked problem.
A HESITANT ALTERNATIVE MODEL TO THE POST-BENCHMARK ERA
Listen, I do think the world remains consistent with ever-increasing AI capabilities, to the degree that large sections of the economy end up automated quite quickly, that AI intellectual ability outstrips most or even all humans in the next few years, and (I’m most hesitant about this last part) that we rapidly end up in some regime of self-improvement that leads to “superintelligence.”
At the same time, the issue is not decided. It is certainly not decided by this one result.
There is still not a single explicit large-scale domain of intellectual production (as in broad categories like writing, math, medicine, science, legal advice, etc.) in which AI has truly surpassed quality human experts, at least over the scope of most jobs (and yes, I include programming) in the same way it surpassed Chess or Go players. E.g., when it comes to writing, it’s been half a decade since LLMs could produce okay-ish prose, yet after all this progress they are still bad enough to be detectably low-quality and so regularly cause scandals.
So there remains the hypothesis that the same slow plateauing (not in benchmarks, but in real-world impact) will play out in all intellectual domains for LLMs, even math and science, just as it did for writing. As I wrote in “Bits In, Bits Out” earlier this year:
LLMs can now “write a scientific paper” or “write a mathematical paper” in the exact same sense that they’ve been able to “write a book” or “write a short story” or “write an essay” for several years, all to some effect, but overall the results have been objectively mediocre given the hype, and the world is somewhat stupider, rather than smarter, at least on average.
Another alternative hypothesis is that various intellectual domains like math and programming will indeed fall in their entirety to AI, but there will be sharp distinctions based on whether the domains are verifiable or (as I think is under-discussed) searchable.
Those three futures (full automation, full approximation, partial automation) would all look like extremely AI-bullish predictions five years ago, mainly because the models have indeed gotten absurdly smart. But, up close, the futures they entail still look incredibly different, don’t they?
THIS IS JUST RIDICULOUS HUMAN COPE
Yes!
Of course it is!
We are well into the era of human cope. We barely have any sources of cope left; we are cope-less, we need an entire copium mining operation to keep up. A human mathematician managed to improve the bound? Go us!


Goal posts are moving rapidly and have been for some time. But there’s also a legitimate argument for why goal posts should indeed move: these subjects are much more complicated from up close, and we are all now very Up Close.
E.g., Helen Toner (ex-OpenAI board member, among many other things) recently wrote about how even the term “AGI” isn’t that useful anymore for talking about the technology of today. In fact, I’m going to borrow her great chart here, as it’s a synecdoche of this all:
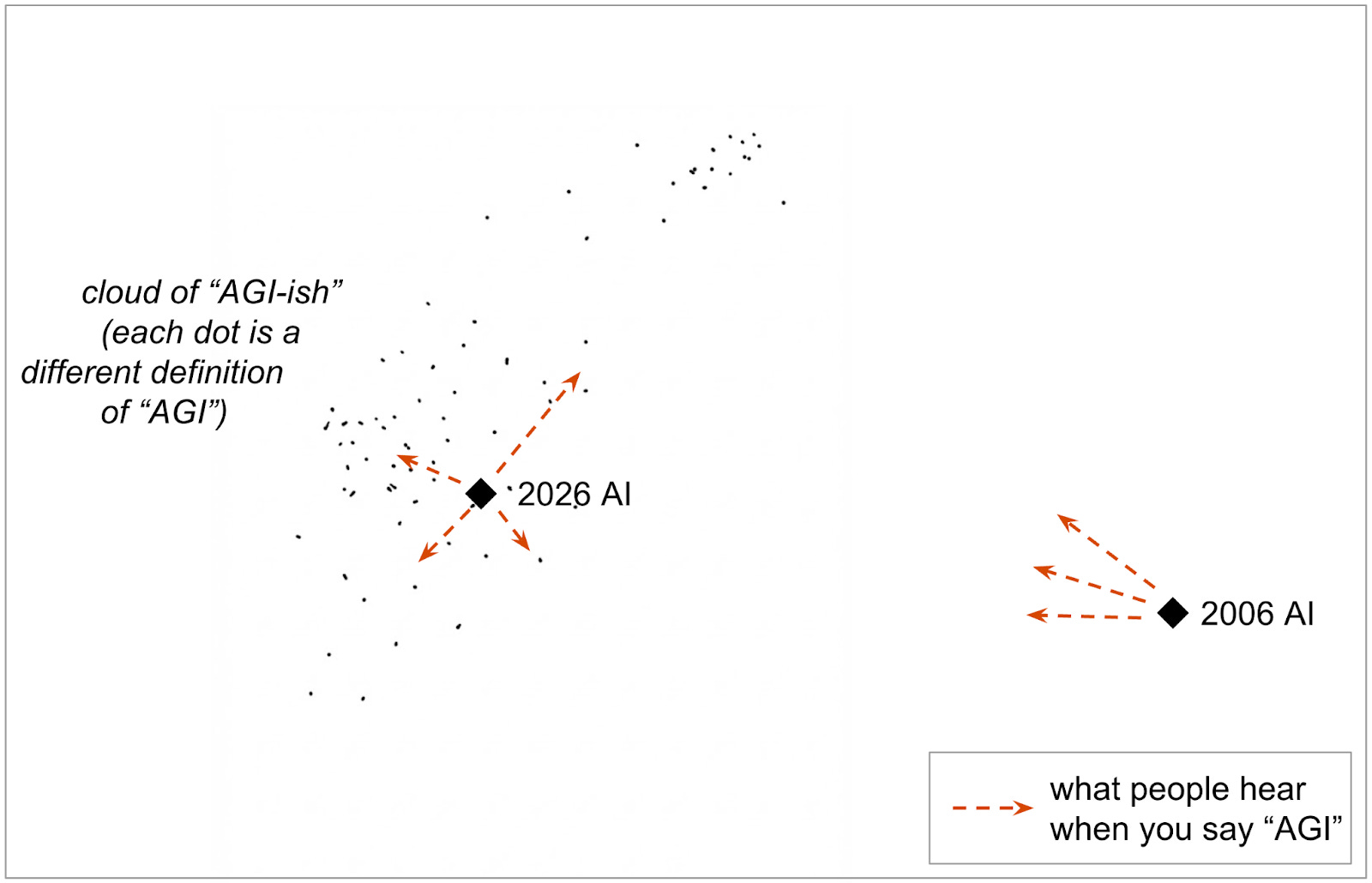
From over on the right, looking out at 2026 from the vantage of 2006, it seems as if “Artificial General Intelligence” has indeed been achieved here in 2026. But if we then zoom into our current AI, it maps onto some definitions of AGI, but not all, and there are no clear lines or borders. In fact, the current definition of “AGI” is so complexified by reality that it’s not a good umbrella term anymore: it dissolves away into a dozen inter-related definitions under the hood (e.g., AI can pass the bar exam, but not even play a simple out-of-distribution video game without human-made harnesses and human interventions).
Similarly, as our notion of what “AGI” is complexifies, so too does our notion of “an AI intellectual contribution” complexify. How much elicitation was involved? Was it attention bottlenecked? Does this actually represent a new capability or can earlier models accomplish it too?
You can’t just sneer at these questions!
Solving such a renowned Erdős problem is indeed historic—and an incredible accomplishment. There is no denying any of that. But now that benchmarks have saturated, and measuring upcoming models’ intelligence has become so difficult, at minimum, we should demand that organizations like OpenAI and Anthropic rigorously control for whether their new much-hyped novel discoveries can actually be replicated with previously existing models. That’s a scientific necessity. Otherwise such discoveries, no matter how amazing, do not actually give us information about new capabilities themselves. Instead, they might simply reflect a long march by already-impressive systems across attention-bottlenecked topics… of which there are more than enough to last until the IPOs.
There are also proofs for all provable theorems in the Library of Babel. I'm not seeing how this is meaningfully different from finding one there.
Like you said, I think science is the domain where ASI fails to materialize, because there is no amount of intelligence that allows you to skip having to do real world experiments, and I think we're pretty far away from fully automated laboratories. Science really is very different from math and programming.