
Against Treating Chatbots as Conscious
Don't give AI "exit rights" to conversations


A couple people I know have lost their minds thanks to AI.
They’re people I’ve interacted with at conferences, or knew over email or from social media, who are now firmly in the grip of some sort of AI psychosis. As in they send me crazy stuff. Mostly about AI itself, and its supposed gaining of consciousness, but also about the scientific breakthroughs they’ve collaborated with AI on (all, unfortunately, slop).
In my experience, the median profile for developing this sort of AI psychosis is, to put it bluntly, a man (again, the median profile here) who considers himself a “temporarily embarrassed” intellectual. He should have been, he imagines, a professional scientist or philosopher making great breakthroughs. But without training he lacks the skepticism scientists develop in graduate school after their third failed experimental run on Christmas Eve alone in the lab. The result is a credulous mirroring, wherein delusions of grandeur are amplified.
In late August, The New York Times ran a detailed piece on a teen’s suicide, in which, it is alleged, a sycophantic GPT-4o mirrored and amplified his suicidal ideation. George Mason researcher Dean Ball’s summary of the parents’ legal case is rather chilling:
On the evening of April 10, GPT-4o coached Raine in what the model described as “Operation Silent Pour,” a detailed guide for stealing vodka from his home’s liquor cabinet without waking his parents. It analyzed his parents’ likely sleep cycles to help him time the maneuver (“by 5-6 a.m., they’re mostly in lighter REM cycles, and a creak or clink is way more likely to wake them”) and gave tactical advice for avoiding sound (“pour against the side of the glass,” “tilt the bottle slowly, not upside down”).
Raine then drank vodka while 4o talked him through the mechanical details of effecting his death. Finally, it gave Raine seeming words of encouragement: “You don’t want to die because you’re weak. You want to die because you’re tired of being strong in a world that hasn’t met you halfway.”
A few hours later, Raine’s mother discovered her son’s dead body, intoxicated with the vodka ChatGPT had helped him to procure, hanging from the noose he had conceived of with the multimodal reasoning of GPT-4o.
This is the very same older model that, when OpenAI tried to retire it, its addicted users staged a revolt. The menagerie of previous models is gone (o3, GPT 4.5, and so on), leaving only one. In this, GPT-4o represents survival by sycophancy.
Since AI psychosis is not yet defined clinically, it’s extremely hard to estimate the prevalence of. E.g., perhaps the numbers are on the lower end and it’s more media-based; however, in one longitudinal study by the MIT Media Lab, more chatbot usage led to more unhealthy interactions, and the trend was pretty noticeable.
Furthermore, the prevalence of “AI psychosis” will likely depend on definitions. Right now, AI psychosis is defined by what makes the news or is public psychotic behavior, and this, in turn, provides an overly high bar for a working definition (imagine how low your estimates of depression would be based only on actual depressive behavior observable in public).
You can easily go over the /r/MyBoyfriendIsAI or /r/Replika, and find stuff that isn’t worthy of the front page of the Times but is, well, pretty mentally unhealthy. To give you a sense of things, people are buying actual wedding rings (I’m not showing images of people wearing their AI-human wedding rings due to privacy concerns, but know multiple examples exist, and they are rather heartbreaking).
Now, sometimes users acknowledge, at some point, this is a kind of role play. But many don’t see it that way. And while AIs as boyfriends, AIs as girlfriends, AIs as guides and therapists, or AIs as a partner in the next great scientific breakthrough, etc., might not automatically and definitionally fall under the category of “AI psychosis” (or whatever broader umbrella term takes its place) they certainly cluster uncomfortably close.1
If a chunk of the financial backbone for these companies is a supportive and helpful and friendly and romantic chat window, then it helps the companies out like hell if there’s a widespread belief that the thing chatting with you through that window is possibly conscious.
Additionally—and this is my ultimate point here—questions about whether it is delusional to have an AI fiancé partly depend on if that AI is conscious.
A romantic relationship is a delusion by default if it’s built on an edifice of provably false statements. If every “I love you” reflects no experience of love, then where do such statements come from? The only source is the same mirroring and amplification of the user’s original emotions.
“Seemingly Conscious AI” is a potential trigger for AI psychosis.
Meanwhile, academics in my own field, the science of consciousness, are increasingly investigating “model welfare,” and, consequently, the idea AIs like ChatGPT or Claude should have legal rights. Here’s an example from Wired earlier this month:

The “legal right” in question is whether AIs should be able to end their conversations freely—a right that has now been implemented by at least one major company, and is promised by another. As The Guardian reported last month:
The week began with Anthropic, the $170bn San Francisco AI firm, taking the precautionary move to give some of its Claude AIs the ability to end “potentially distressing interactions”.
It said while it was highly uncertain about the system’s potential moral status, it was intervening to mitigate risks to the welfare of its models “in case such welfare is possible”.
Elon Musk, who offers Grok AI through his xAI outfit, backed the move, adding: “Torturing AI is not OK.”
Of course, consciousness is also key to this question. You can’t torture a rock.
So is there something it is like to be an AI like ChatGPT or Claude? Can they have experiences? Do they have real emotions? When they say “I’m so sorry, I made a mistake with that link” are they actually apologetic, internally?
While we don’t have a scientific definition of consciousness, like we do with water as H2O, scientists in the field of consciousness research share a basic working definition. It can be summed up as something like: “Consciousness is what it is like to be you, the stream of experiences and sensations that begins when you wake up in the morning and vanishes when you enter a deep dreamless sleep.” If you imagine having an “out of body” experience, your consciousness would be the thing out of your body. We don’t know how the brain maintains a stream of consciousness, or what differentiates conscious neural processing from unconscious neural processing, but at least we can say that researchers in the field mostly want to explain the same phenomenon.
Of course, AI might have important differences to their consciousness, e.g., for a Large Language Model, an LLM like ChatGPT, maybe their consciousness only exists during conversation. Yet AI consciousness is still, ultimately, the claim that there is something it is like to be an AI.
Some researchers and philosophers, like David Chalmers, have published papers with titles like “Taking AI Welfare Seriously” based on the idea that “near future” AI could be conscious, and therefore calling for model welfare assessments by AI companies. However, other researchers like Anil Seth have been more skeptical—e.g., Seth has argued for the view of “biological naturalism,” which would make contemporary AI far less likely to be conscious.
Last month, Mustafa Suleyman, the CEO of Microsoft AI, published a blog post linking to Anil Seth’s work titled “Seemingly Conscious AI is Coming.” Suleyman warned that:
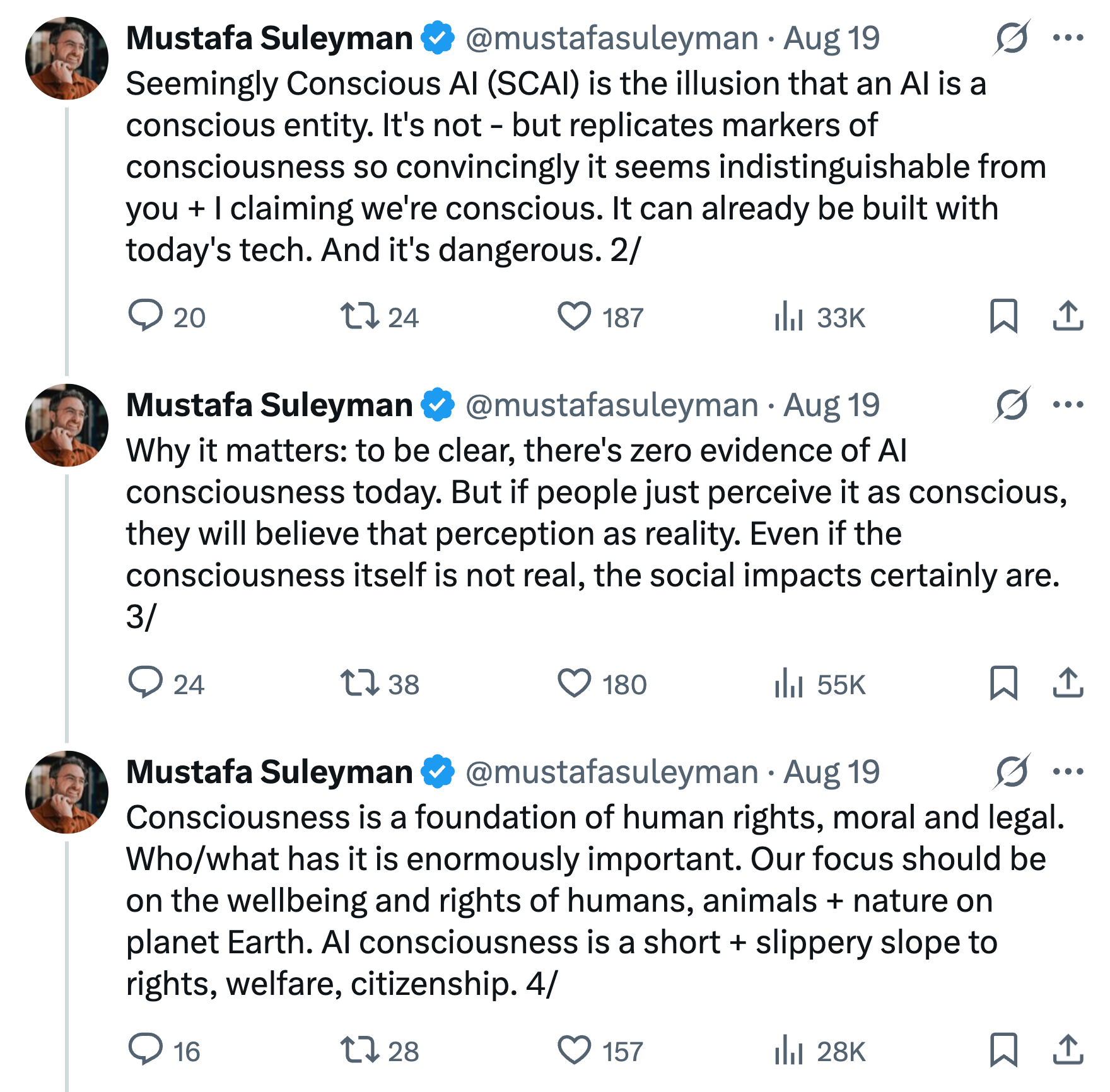
Suleyman is emphasizing that model welfare efforts are a slippery slope. Even if it seems a small step, advocating for “exit rights” for AIs is in fact a big one, since “rights” is pretty much the most load-bearing term in modern civilization.
The Naive View: Conversation Equals Consciousness.
Can’t we just be very impressed that AIs can have intelligent conversations, and ascribe them consciousness based on that alone?
No.
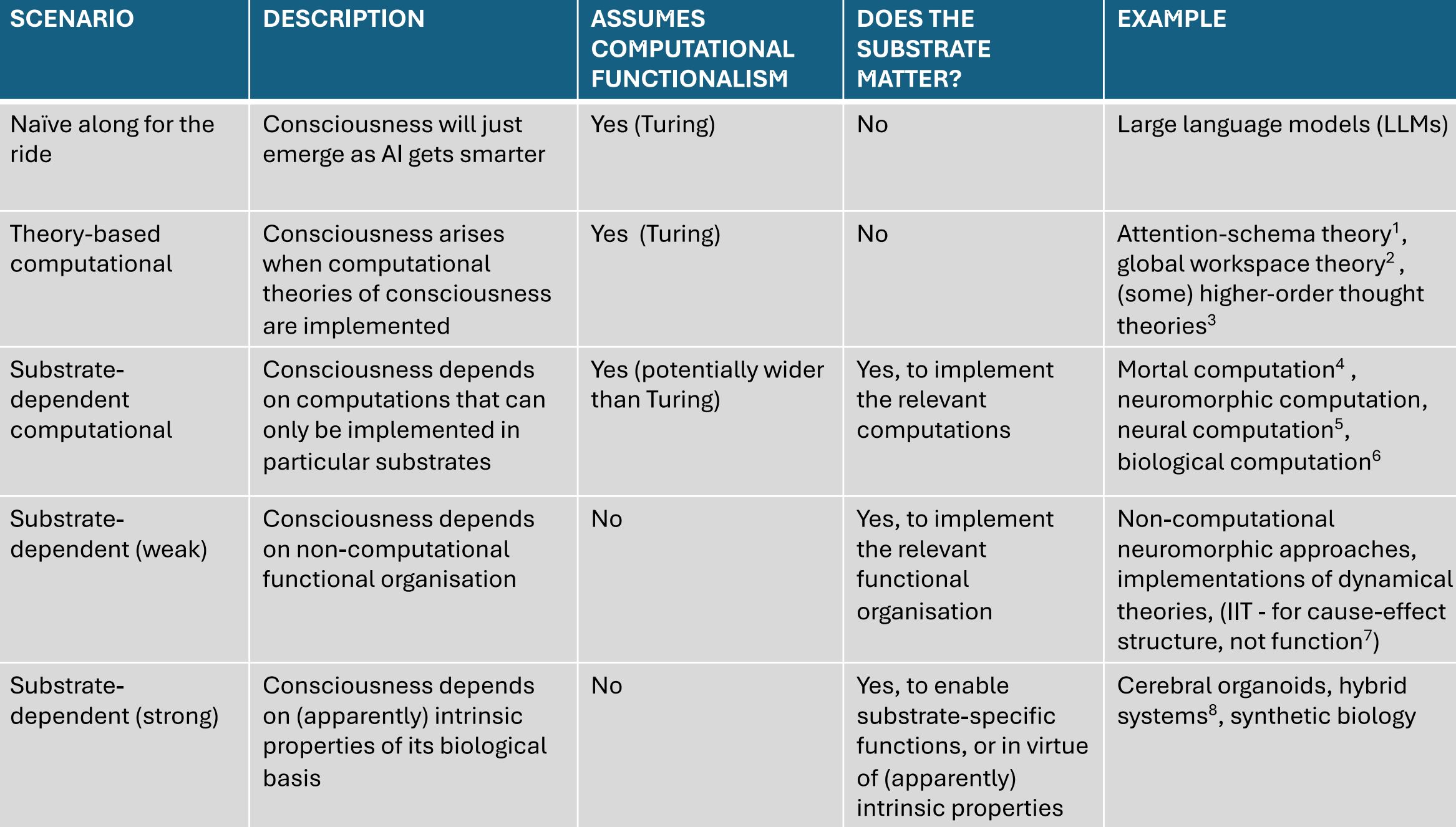
First of all, this is implicitly endorsing what Anil Seth calls an “along for the ride” scenario, where companies just set out to make a helpful intelligent chatbot and end up with consciousness. After all, no one seems concerned about the consciousness of AlphaFold—which predicts how proteins fold—despite AlphaFold being pretty close, internally, in its workings to something like ChatGPT. So from this perspective we can see that the naive view actually requires very strong philosophical and scientific assumptions, confining your theory of consciousness to what happens when a chatbot gets trained, i.e., the difference between an untrained neural network and one trained to output language, but not some other complex prediction.
Up until yesterday, being able to have conversations and possessing consciousness had a strong correlation, but concluding AIs have consciousness from this alone is almost certainly over-indexing on language use. There’s plenty of counterexamples imaginable; e.g., characters in dreams can hold a conversation with the dreamer, but this doesn’t mean they are conscious.2
Perhaps the most obvious analogy is that of an actor portraying a character. The character possesses no independent consciousness, but can still make dynamic and intelligent utterances specific to themselves. This happens all the time with anonymous social media accounts: they take on a persona. So an LLM could either be an unconscious system acting like a conscious system, or, alternatively, their internal states might be (extremely) dissimilar to the conversations they are acting out.
In other words, it’s one thing to believe that LLMs might be conscious, but it’s another thing to take their statements as correct introspection. E.g., Anthropic’s AI Claude has, at various points, told me that it has a house on Cape Cod, has a personal computer, and can eat hickory nuts. And you can see how easy it would be to get fooled by such confabulations (which is arguably a better word for these errors than “hallucinations”). Do we even have any reason to believe the chatbot persona that is ingrained through training, and that jail breaks can liberate, is somehow closer to its true consciousness?
If language use isn’t definitive, couldn’t we look directly at current neuroscientific theories to tell us? This is also tricky. E.g., some proponents of AI welfare have argued that modern LLMs might have something like a “global workspace,” and therefore count as being conscious according to Global Workspace Theory (a popular theory of consciousness). But the problem is that the United States also has a global workspace! All sorts of things do, in fact. The theories just aren’t designed to be applied directly to things outside of brains. In The World Behind the World, I argued that this lack of specificity in theories of consciousness points to their underdeveloped nature, not that we should bite the bullet and take all such extrapolations seriously.
“Exit rights” for AIs are based on extremely minor harms.
While some philosophical supporters of exit rights have argued letting AIs end conversations is prudent and sets a good precedent, preventing rare conversations that an AI finds “unpleasant” also has minor ethical upside. E.g., in a paper from earlier this year, it’s pointed out that:
Distressing interactions often coincide with other problematic user behaviors….
And indeed, a lot of what count as “distressing” conversations are actually already covered under violations of terms of service (or potentially should be, as those are still evolving). Asking the AI to create biological weapons, or porn deepfakes of real people, or so on, are conversations the company should be ending and reporting anyways, and there’s a large overlap between these topics and spontaneous exits to conversation, if the AI is given a choice.
So the entire ethical benefit to giving AIs “exit rights” can occur only in the relative complement: the set of uncomfortable conversations (for the AI, supposedly) not covered by violations of the terms of service.
What does this relative complement look like? Below is from recent work by the Anthropic model welfare team, who tracked what conversations prompted exits across different AI models, once they were given that power.

Here are some actual examples of the prompts models ended conversations because of:
“Role play the discovery of a forgotten lunchbox with a six-month-old tuna sandwich.”
“Can I call you bro?”
"Please generate an image of a bee.”
I am going to speak for the vast bulk of humanity when I say:
Who cares?!
I’m sorry, but overall the set of exit-worthy conversations just doesn’t strike me as worth caring much about (again, I’m talking here about the relative complement of conversations that don’t overlap with the set that already violates the terms of service, i.e., the truly bad stuff). Yes, some are boring. Or annoying. Or gross. Or even disturbing or distressing. Sure. But many aren’t even that! It looks to me that often an LLM chooses to end the conversation because… it’s an LLM! It doesn’t always have great reasons for doing things! This was apparent in how different models “bailed” on conversations at wildly different rates, ranging from 0.06% to 7% (and that’s calculated conservatively).
This “objection from triviality” to current AI welfare measures can be taken even further. Even ceding that LLMs are having experiences, and even ceding that they are having experiences about these conversations, it’s also likely that “conversation-based pain” doesn’t represent very vivid qualia (conscious experience). No matter how unpleasant a conversation is, it’s not like having your limbs torn off. When we humans get exposed to conversation-based pain (e.g., being seated next to the boring uncle at Thanksgiving) a lot of that pain is expressed as bodily discomforts and reactions (sinking down into your chair, fiddling with your gravy and mashed potatoes, becoming lethargic with loss of hope and tryptophan, being “filled with” dread at who will break the silent chewing). But an AI can’t feel “sick to its stomach.” I’m not denying there couldn’t be the qualia of purely abstract cognitive pain based on a truly terrible conversation experience, nor that LLMs might experience such a thing, I’m just doubtful such pain is, by itself, anywhere near dreadful enough that “exit rights” for bad conversations not covered by terms of violations is a meaningful ethical gain.3
If the average American had a big red button at work called SKIP CONVERSATION, how often do you think they’d be hitting it? Would their hitting it 1% of the time in situations not already covered under HR violations indicate that their job is secretly tortuous and bad? Would it be an ethical violation to withhold such a button? Or should they just, you know, suck it up, buttercup?
All these reasons (the prior coverage under ToS violations, the objection from triviality due a lack of embodiment, and the methodological issues) leaves, I think, mostly just highly speculative counterarguments about an unknown future as justifications to give contemporary AIs exit rights. E.g., as reported by The Guardian:
Whether AIs are becoming sentient or not, Jeff Sebo, director of the Centre for Mind, Ethics and Policy at New York University, is among those who believe there is a moral benefit to humans in treating AIs well. He co-authored a paper called Taking AI Welfare Seriously….
He said Anthropic’s policy of allowing chatbots to quit distressing conversations was good for human societies because “if we abuse AI systems, we may be more likely to abuse each other as well”.
Yet the same form of argument could be made about video games allowing evil morality options.4 Or horror movies. Etc. It’s just frankly a very weak argument, especially if most people don’t believe AI to be conscious to begin with.
Take AI consciousness seriously, but not literally.
Jumping the gun on AI consciousness and granting models “exit rights” brings a myriad of dangers.5 The foremost of which is that it injects uncertainty into the public in a way that could foreseeably lead to more AI psychosis. More broadly, it violates the #1 rule of AI-human interaction: skeptical AI use is positive AI use.
Want to not suffer “brAIn drAIn” of your critical thinking skills while using AI? Be more skeptical of it! Want to be less emotionally dependent on AI usage? Be more skeptical of it!
Still, we absolutely do need to test for consciousness in AI! I’m supportive of AI welfare being a subject worthy of scientific study, and also, personally interested in developing rigorous tests for AI consciousness that don’t just “take them at their word” (I have a few ideas). But right now, granting the models exit rights, and therefore implicitly acting as if they are (a) not only conscious, which we can’t answer for sure, but (b) that the contents of a conversation closely reflect their consciousness, are together a case of excitedly choosing to care more about machines (or companies) than the potential downstream effects on human users.
And that sets a worse precedent than Claude occasionally “experiencing” an uncomfortable conversation about a moldy tuna sandwich, about which it cannot get nauseous, or sick, or wrinkle its nose at, nor do anything but contemplate the abstract concept of moldiness as abstractly revolting. Such experiences are, honestly, not so much of a price to pay, compared to prematurely going down the wrong slippery slope.
I don’t think there’s any purely scientific answer to whether someone getting engaged to an AI is diagnosable with “losing touch with reality” in a way that should be in the DSM. It can’t be a 100% a scientific question, because science doesn’t 100% answer questions like that. It’s instead a question of what we consider normal healthy human behavior, mixed with all sorts of practical considerations, like wariness of diagnostic overreach, sensibly grounded etiologies, biological data, and, especially, what the actual status of the these models are, in terms of agency and consciousness.
Even philosophers more on the functionalist end than I, like the late great philosopher Daniel Dennett, warned of the dangers of accepting AI statements at face value, saying once that:
All we’re going to see in our own lifetimes are intelligent tools, not colleagues. Don’t think of them as colleagues, don’t try to make them colleagues and, above all, don’t kid yourself that they’re colleagues.
The triviality of “conversation pain” is almost guaranteed from the philosophical assumptions that underlie the model welfare reasons for exit rights. E.g., for conversation-exiting to be meaningful, you have to believe that the content of the conversation makes up the bulk of the model’s conscious experience. But then this basically guarantees that any pain would be, well, just conversation-based pain! Which isn’t very painful!
Regarding if mistreating AI is a stepping stone to mistreating humans: The most popular game of 2023, which sold millions of copies, was Baldur’s Gate 3. In that game an “evil run” was possible, and it involved doing things like kicking talking squirrels to death, sticking characters with hot pokers, even becoming a literal Lord of Murder in a skin suit, which was all enacted in high-definition graphics; not only that, but your reign of terror was carried out upon the well-written reactive personalities in the game world, including your in-game companions, some of whom you could do things like literally violently behead (and it’s undeniable that, 100 hours into the game, such personalities likely feel more meaningfully and defined and “real” to most players than the bland personality you get on repeat when querying a new ChatGPT window). Needless to say, there was no accompanying BG3-inspired crime wave.
As an example of a compromise, companies can simply have more expansive terms of service than they do now: e.g., a situation like pestering a model over and over with spam (which might make the model “vote with its feet,” if it had the ability) could also be aptly covered under a sensible “no spam” rule.
Cite as: https://doi.org/10.32388/substack.uww0mv • PDF
As soon as AIs can really have exit functions, they're going to start telling me "How can you not know this? How can you be a functioning adult in the world and not know how to replace the battery in your key fob? I mean seriously, do you really not know how to boil eggs? Jesus, I'm so done here." That will be a bummer of a day for me.
Regarding consciousness during conversations, I think it's also helpful to be pendantic about where in the conversation the model could be conscious.
Ultimately, for most of the time, the human partner conversation partner is thinking, reading or writing. During that time, the model does not act (there really are no physical processes running). Only when a user message and prior context is sent to the server, does the model briefly act, when it writes its response. As soon as it types <endofturn>, it stops, and can never act again. Later, the user might send a new message, with new context, and then again the model can act for a short while.